I have a theory about Anthropic's recent blog post "When AI Builds Itself," in which they requested:
"We believe it would be good for the world to have the option to slow or temporarily pause frontier AI development to enable societal structures and alignment research to keep up with the advance of the technology."
What I'm questioning is whether this is genuine goodwill or a smokescreen for a technical failure driven by data poisoning, diminishing returns, and public market economics.
Correcting the Scaling Law Assumptions
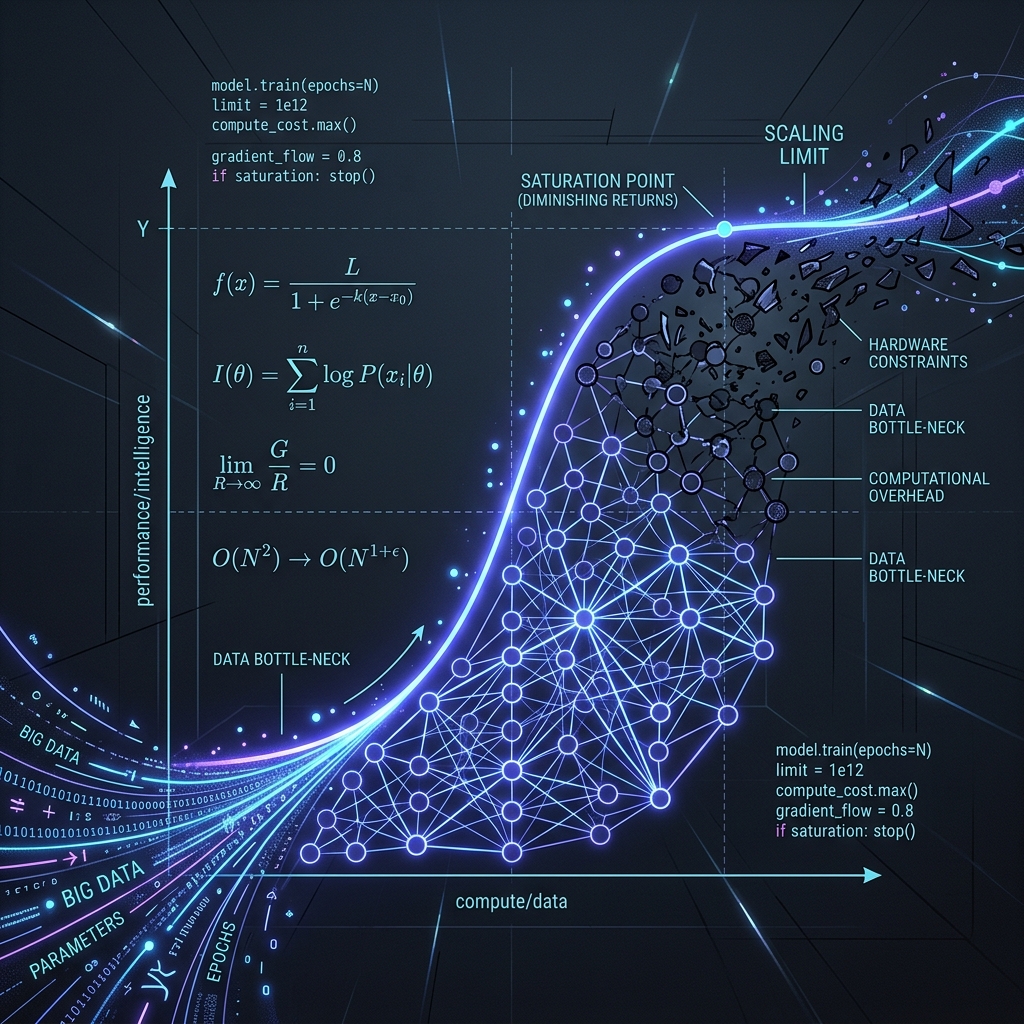
Early scaling hypotheses (Kaplan et al., 2020) suggested throwing compute almost entirely at model size. The modern compute-optimal scaling law, formalized by DeepMind's Hoffmann et al. (2022) in the "Chinchilla" paper, corrected this:
You cannot just scale parameters (N); you must scale the dataset (D) in roughly equal proportion. But there is a hidden trap: the term E. This represents irreducible error, the inherent entropy of text. As parameters and data approach infinity, loss asymptotes at E rather than dropping to zero. An eventual plateau is mathematically baked in. The critical economic question is whether we are hitting that asymptote now.
The Data Poisoning Problem
The Chinchilla law assumes dataset D is high-quality, human-generated text. That assumption is breaking down. The internet is now heavily polluted with LLM-produced content, and when models train recursively on synthetic output from other models, they suffer from Model Collapse (Shumailov et al., 2023). The tails of the data distribution disappear, model understanding degrades, and error rates climb. This provides a clear catalyst for the inverse scaling documented by McKenzie et al. (2023), where more poisoned data fed into larger models actually worsens complex reasoning.
Capabilities Follow S-Curves
Even if cross-entropy loss continues dropping slowly, economic capabilities (passing the bar exam, writing reliable code) do not scale linearly with it. As Schaeffer et al. (2023) showed, emergent abilities follow sigmoidal S-curves. A model hits a loss threshold, unlocks a capability, and performance then flattens at the top of the curve. Spending ten times the compute to squeeze out the next 0.01 drop in loss may yield zero new monetizable capabilities.
The Mythos Black Box
Anthropic has released no technical details about Claude Mythos: no parameter count, no training token count, no compute figures. There is open speculation that Mythos is among the largest models ever trained, possibly the largest, with a token count to match. If true, Anthropic may have run the most expensive experiment in AI history and hit the data poisoning wall harder than anyone. At that scale you cannot quietly retrain while telling investors everything is on track. The pause request reframes this cleanly: rather than disclosing that the largest training run ever attempted may have underperformed, or that the next run requires solving a fundamental data quality problem first, you shift the narrative to safety and societal readiness. The timing and the financial incentives make that reframing at minimum convenient, and at maximum deliberate.
The IPO and the Euphemism
Anthropic recently submitted a confidential draft S-1 to the SEC. If you are heading into a highly anticipated IPO, how do you explain to Wall Street that compute-optimal scaling is hitting a wall? How do you justify hundred-billion-dollar data center CapEx if your dataset is poisoned and your capability curve has flattened?
You reframe it. Anthropic's writing on Recursive Self-Improvement warns of a near-future where AI models rapidly accelerate their own development, requiring a pause for societal safety. If my theory holds, they are recasting a mundane engineering plateau as an optimistic near-apocalypse. Rather than telling public markets "we are running out of pristine human data," they say "we are dangerously close to a runaway intelligence explosion."
A call to pause becomes a financial strategy: slow unsustainable cash burn, prevent open-source competitors from catching up while the synthetic data problem gets solved, and protect valuation heading into an IPO roadshow.
They are not pausing because AI is becoming dangerous. They are pausing because the current paradigm is running out of gas.
Note: This is speculative economic and technical analysis and does not constitute financial advice.